
I’d been building a memory system for my Claude Code setup for weeks before Iit became clear I was solving a common problem in the wrong way.
Memory plugins are everywhere – activity logs, vector databases, episodic recall, semantic search over past sessions. And I built one too, because it seemed like an obvious productivity gain. But the more I used it, the more I noticed something odd: the agent would read the memories, acknowledge them, and then walk into the exact same traps anyway – issues that i’d solved already.
Quick Navigation
Jump directly to what you’re looking for:
The trend is memory |
What’s wrong with memory plugins? |
What I really needed |
How it works |
The seesaw problem |
Reinforcement tracking |
Getting started |
What to watch out for
The trend is memory. But is it that simple?
The Claude Code ecosystem is flooded with memory solutions. Claude-Mem, Memsearch, Agent Memory MCP, Cognee, SuperMemory – there’s a new one every week. They all do roughly the same thing: capture what the agent did during a session, compress it, store it in a SQLite database or a vector store, then dump the relevant bits back into the context window next time around.
I figured I’d pipe all the session data into a database, summarise it, feed it back in next time, and the agent would just… remember. Like giving it a diary to read before starting work. As if all of a sudden that would be the magic bullet for Claude to sort of take over my life and do everything perfectly from now on. Nope.
If memory was the real problem, the AI companies would’ve solved it already. Anthropic, OpenAI, Google – they’re not exactly short on engineers, are they? Models already learn from our inputs, collectively, across millions of conversations. But we’ve got to wait for the next model release to benefit from that. And even then, it’s generic. Everyone’s patterns averaged together, not yours.
So what’s wrong with memory plugins?
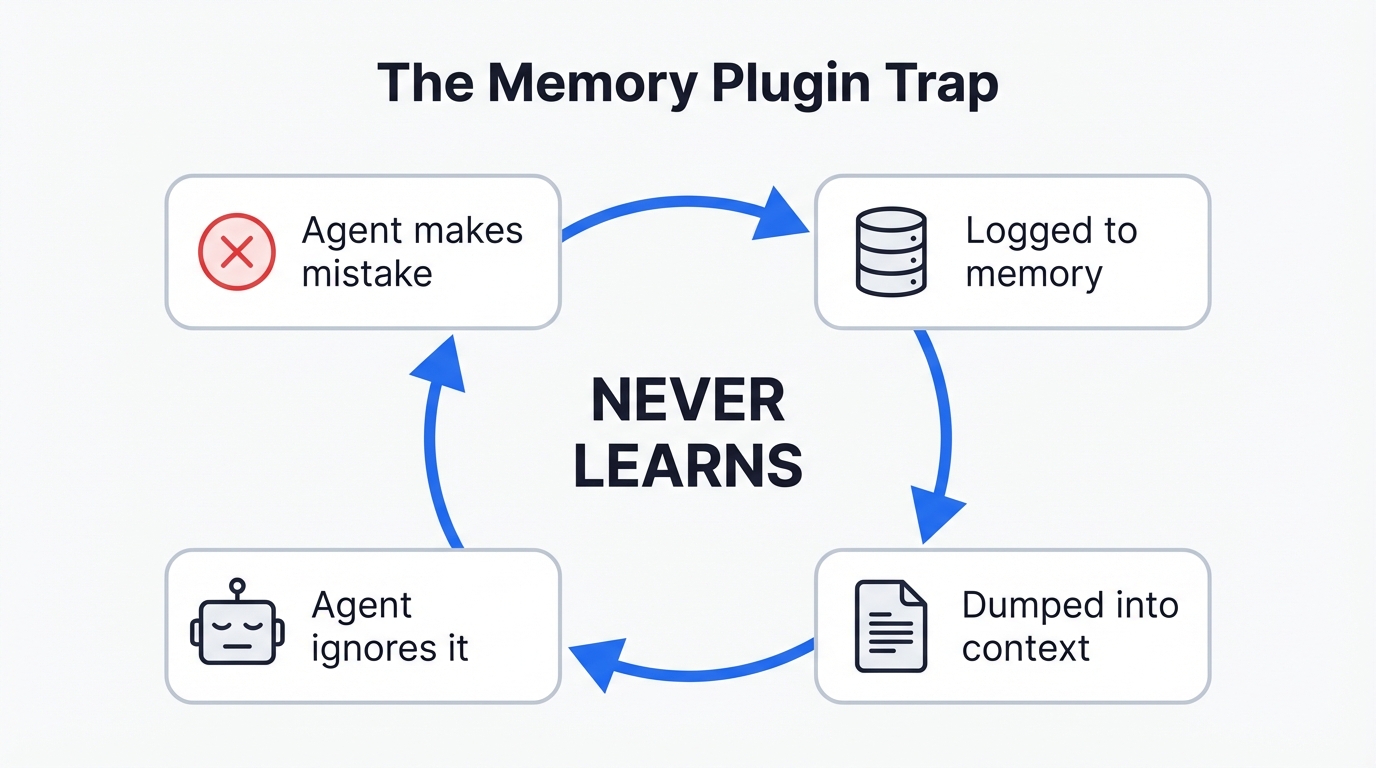
The fundamental problem with memory plugins isn’t stale data or token costs (though those are real problems too). It’s that they treat the agent’s context window like a filing cabinet. When a new session starts, they dump a stack of past observations into the prompt and hope the agent pays attention.
It’s like trying to teach someone to ride a bike by making them read a physics textbook while they’re pedalling. The agent drowns in the report and walks right into the same trap.
I’ve watched this happen first hand: Claude-Mem would inject a perfectly accurate summary of what went wrong last session. Claude would read it, acknowledge it, and then do the exact same thing again three tool calls later. Not because the memory was bad. Because the agent doesn’t feel that information the way it feels, say, a syntax error in its face.
There’s a term for this in the research literature – the “Passive Librarian Problem”. The memory system waits for the agent to choose to search, pulls a bunch of text, and dumps it into the context. But the agent has to know what it forgot in order to ask for it. Which is, obviously, a bit of a paradox.
What I really needed
What I needed wasn’t better memory. It was something closer to a nervous system – real-time, low-level awareness of operational state. Not “here’s what you did wrong last Tuesday” but “you’re going in circles right now.”
You don’t avoid walking into walls because some “Collision Detection Module” writes a report about a recent impact. You avoid them because your nervous system gives you immediate, low-latency, non-verbal feedback about where your body is and what’s around it. There’s a name for this in philosophy – the Extended Mind Thesis (Clark and Chalmers, 1998) – the idea that cognition doesn’t just happen in the brain, it happens in the loop between a system and its environment.
So I built Metacog. Two Claude Code hooks. Zero dependencies. About 400 lines of JavaScript. And frankly, it’s changed how I think about this stuff entirely.
How it works
Two hooks. One fires after every tool call (that’s the nervous system), the other fires once per session (the reinforcement injector). When everything’s normal, both produce zero output and cost zero tokens. When something’s off, a short signal gets injected into the agent’s context. Not a command – just awareness. The agent’s own reasoning decides what to do with it.
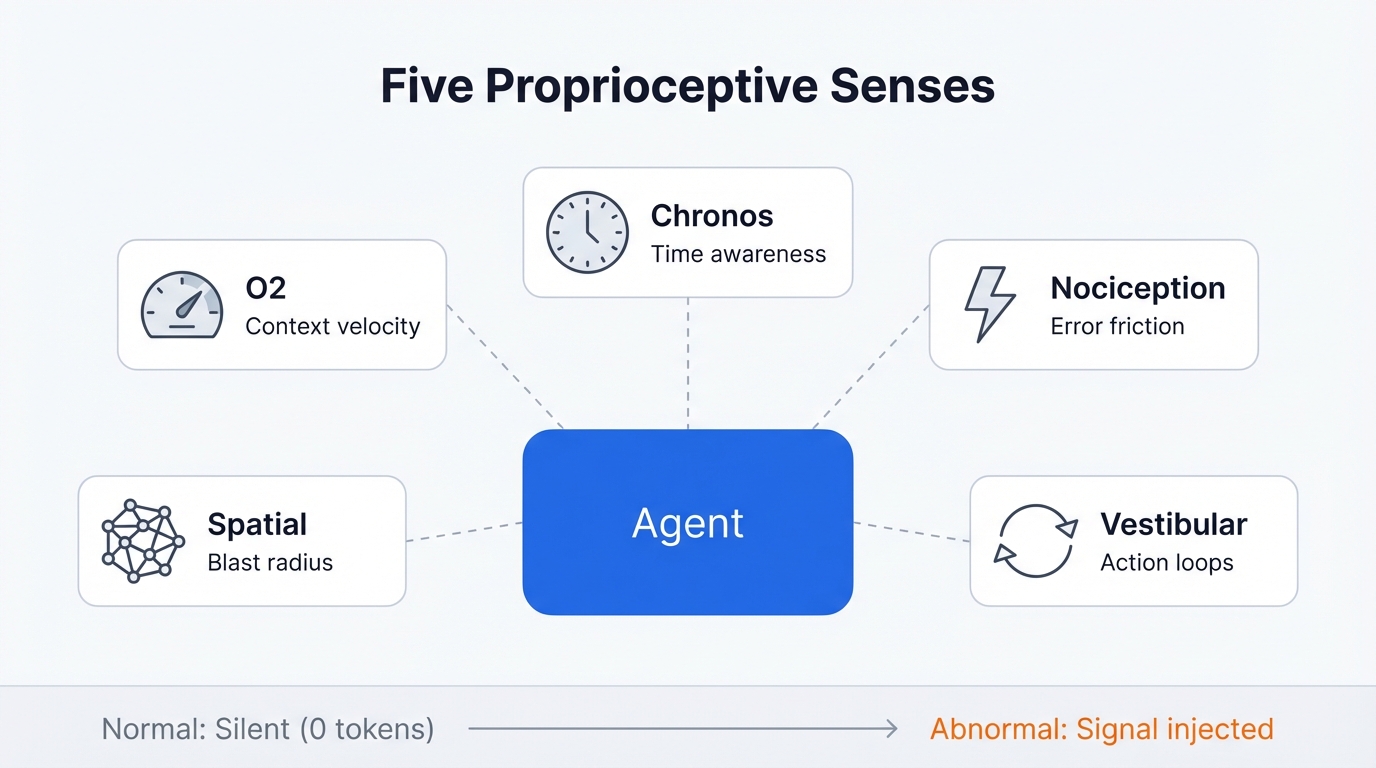
The five senses
I ended up building five proprioceptive sensors, each targeting a specific blindspot that I kept running into with coding agents:
O2 – Context Trend. The agent can’t see its own context window filling up. This is its most critical blindspot – context overflow triggers compaction, which erases in-progress work and causes those maddening infinite retry loops. O2 tracks token velocity – how fast the context is being consumed compared to baseline. When it spikes (three large file reads in a row, for example), the agent gets a signal.
Chronos – Temporal Awareness. Agents have no sense of time. None at all. A 45-minute task feels identical to a 2-minute one. Chronos tracks wall-clock time and step count since the last user interaction. After 15 minutes or 25 tool calls without a user message, the agent gets a nudge.
Nociception – Error Friction. Individual errors are visible to the agent, but the pattern of repeated failure isn’t – and that’s the killer. Three consecutive similar errors triggers a signal. Same error repeated means stuck. Different errors means exploring. That distinction matters a lot.
Spatial – Blast Radius. The agent only sees the file it’s editing right now. It’s got no peripheral vision of how changes propagate through the rest of the codebase. After a file write, Metacog counts how many other files import the modified module. If it’s 14 files, the agent should probably know about that before it starts refactoring.
Vestibular – Action Diversity. The agent can enter silent loops – repeating the same searches, reading the same files, running the same commands – without realising it’s going in circles. Vestibular detects this and breaks the loop.
Three layers of response
Layer 1: Proprioception – always on, near-zero cost. Calculates all five senses after every tool call. Most turns: completely silent. Only fires when values deviate from baseline.
[Proprioception]
Context filling rapidly - 3 large file reads in last 5 actions.
Consider summarising findings before proceeding.Layer 2: Nociception – triggered when Layer 1 thresholds get critical. This is the pain response. It forces a cognitive shift with escalating interventions. First time: Socratic questioning (“State the assumption you’re operating on. What would falsify it?”). Second time: directive instructions. Third time: it flags the user directly.
[NOCICEPTIVE INTERRUPT]
You have attempted 4 similar fixes with consecutive similar errors.
Before taking another action:
1. State the assumption you are currently operating on
2. Describe what read-only action would falsify that assumption
3. Execute that investigation before writing any more codeLayer 3: Reinforcement tracking – the cross-session piece. This is the bit I’m most pleased with, and it came out of a failure that took me ages to diagnose.
The seesaw problem
So, I ran into this really frustrating problem when I tried to bolt on cross-session learning using standard time-decay.
There’s an Experiential RL paper (arxiv 2602.13949) that shows how reflecting on failures at training time improves agent performance by up to 81%. So I built a system that detected failure patterns, recorded rules to prevent them, and injected those rules into the next session. And it worked. For a while.
But then the rules started disappearing.
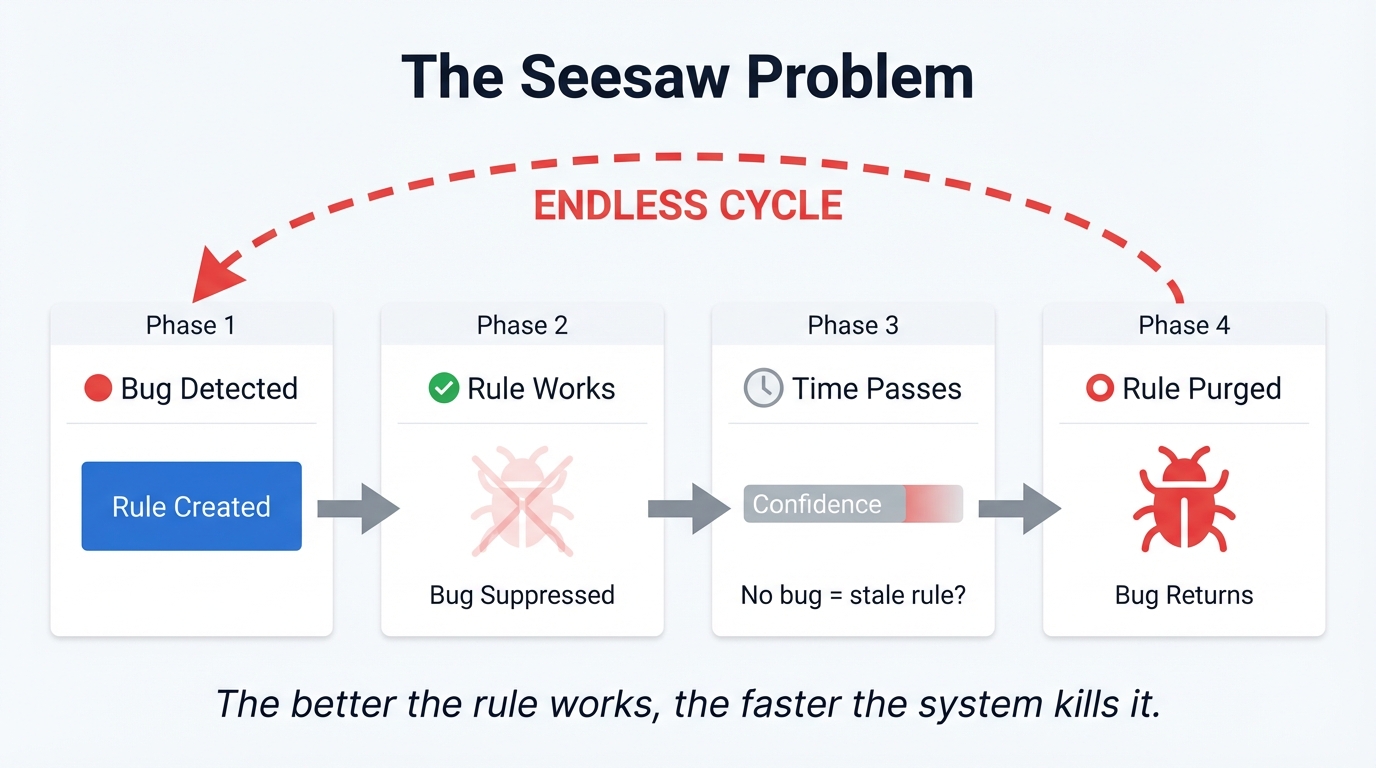
The problem is that naive time-decay actively punishes success. If the agent learns “don’t retry the same error three times” and then it stops retrying the same error, the decay system sees the rule going stale – no recent detections, must be irrelevant – and prunes it. So the agent forgets the rule. And then the behaviour regresses, the rule fires again, confidence climbs, the behaviour improves, the rule decays again. Seesaw.
The better the rule works, the faster the system kills it. That’s not learning. That’s an oscillation.
Reinforcement tracking – fixing the seesaw
To fix the seesaw, I had to invert the decay model entirely.
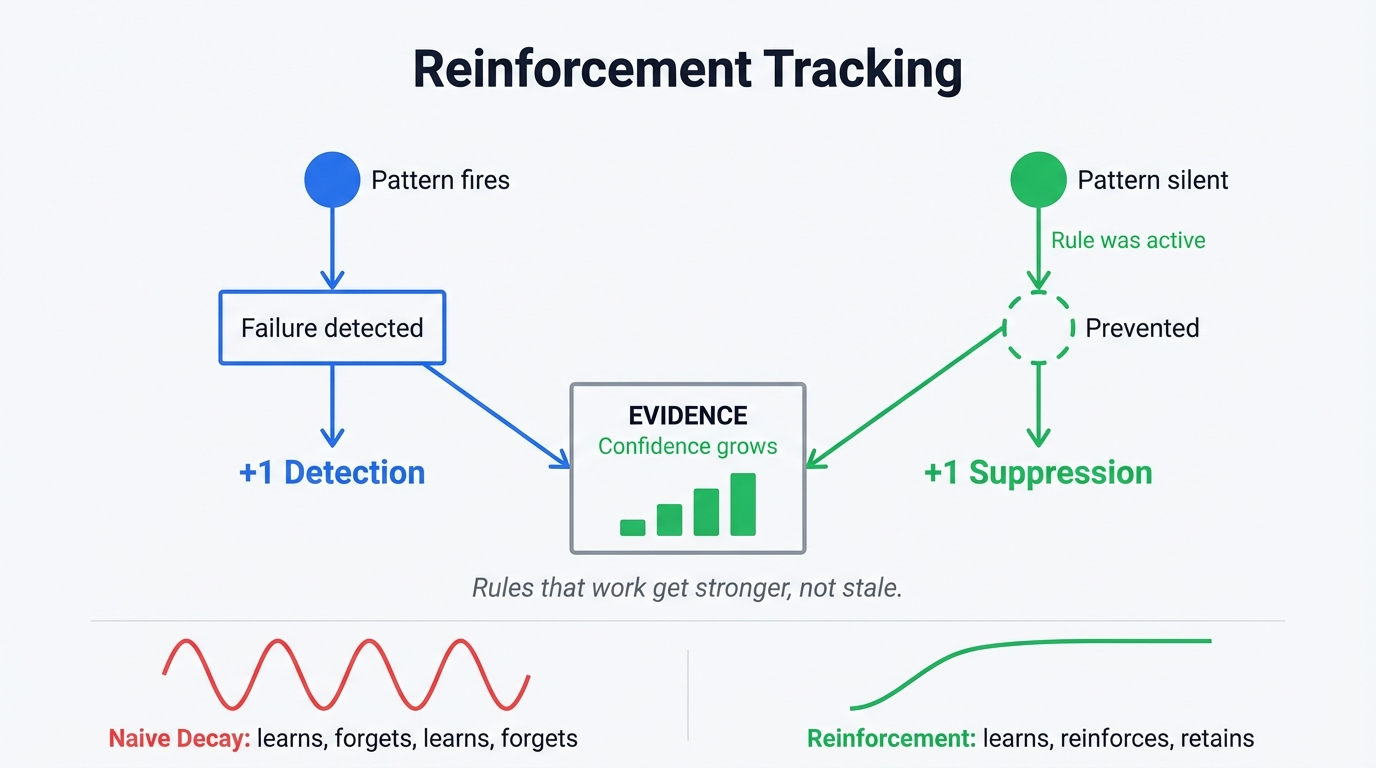
When the nervous system detects a failure pattern, it records a detection – the problem happened. But when a known pattern doesn’t fire during a session where its rule was active, that’s not nothing. That’s evidence the rule is working. The system records a suppression alongside the original detection. Both count as evidence. Both increase confidence.
Rules that successfully suppress their target failure get reinforced by their own success. Only truly dormant rules – patterns that haven’t been active at all for 60+ days – decay. And even then, slowly.
And that’s what makes this different from a memory plugin. It’s not replaying what happened last week. It’s tracking what works, what doesn’t, and building confidence over time about rules that actually prevent the failures you’ve hit. Your patterns. Your failure modes. Your projects. Not everyone else’s averaged together.
How the data flows in practice
When a new session starts, the UserPromptSubmit hook compiles all learnings (global and project-scoped) into a short digest and injects it as a system-reminder. It also writes a marker file with the pattern IDs that were injected – that’s how the system knows which rules were “active” during the session.
During the session itself, the PostToolUse hook fires after every tool call, recording actions into a rolling 20-item window. Silent when normal. Signals when abnormal. No learning happens here – this is pure proprioception.
When the next session starts, the system reads the active patterns marker from last time, runs the detectors against the previous session state, and records what happened. Patterns that fired get logged as detections. Patterns that didn’t fire but were in the active set get logged as suppressions. Both persisted to a JSONL file.
Per-project scoping
Learnings live at two levels. Global (~/.claude/metacog-learnings.jsonl) covers patterns that show up everywhere. Project-scoped (<project>/.claude/metacog-learnings.jsonl) covers patterns specific to one codebase. At compilation, both get merged – project-scoped entries take precedence. So a pattern that only shows up in one repo builds evidence for that repo specifically, without polluting the global set.
Getting started
npx @houtini/metacog --installThat drops both hooks into your global Claude Code settings. For per-project installation:
npx @houtini/metacog --install --projectAnd that’s it. Metacog runs silently. You’ll only see output when something is abnormal.
What to watch out for
1. Don’t expect immediate results. Reinforcement tracking needs a few sessions to build evidence. The proprioceptive layer works from the first tool call, but the cross-session learning takes time to calibrate.
2. The spatial sense can be slow on very large codebases. It runs grep-based import detection, which is fast on most projects but might add latency on monorepos with thousands of files. You can disable it in config if needed.
3. It’s Claude Code only. This uses Claude Code hooks (PostToolUse and UserPromptSubmit), so it won’t work with Claude Desktop, Cursor, or other clients. That’s by design – hooks give us the stderr injection path that makes zero-token-cost silence possible.
4. The nociceptive interrupt can feel aggressive. When it fires, it literally tells the agent to stop and reflect. Some people find this jarring. But honestly, if the agent has hit four consecutive similar errors, being polite about it isn’t helping anyone.
Metacog is open source under Apache 2.0. Zero dependencies. The source is the distribution.
Related Articles

Yet Another Memory MCP? That’s Not the Memory You’re Looking For
I’d been building a memory system for my Claude Code setup for weeks before Iit became clear I was solving a common problem in the wrong way. Memory plugins are everywhere – activity logs, vector databases, episodic recall, semantic search over past sessions. And I built one too, because it seemed like an obvious productivity … <a title="AI SEO – A Tool to Help You Improve Your Content for AI Search" class="read-more" href="https://houtini.com/aiseo/" aria-label="Read more about AI SEO – A Tool to Help You Improve Your Content for AI Search">Read more</a>

The Best MCPs for Content Marketing (Research, Publish, Measure)
Most front line content marketing workflow follows the same loop. Find something worth writing about, dig into what’s already ranking on your site, update or write it, run it through SEO checks, shove it into WordPress, then wait to see if anyone reads it. Just six months ago that loop was tedious tab-switching and copy-pasting. … <a title="AI SEO – A Tool to Help You Improve Your Content for AI Search" class="read-more" href="https://houtini.com/aiseo/" aria-label="Read more about AI SEO – A Tool to Help You Improve Your Content for AI Search">Read more</a>
How to Set Up LM Studio: Running AI Models on Your Own Hardware
How does anyone end up running their own AI models locally? For me, it started because of a deep interest in GPUs and powerful computers. I’ve got a machine on my network called “hopper” with six NVIDIA GPUs and 256GB of RAM, and I’d been using it for various tasks already, so the idea of … <a title="AI SEO – A Tool to Help You Improve Your Content for AI Search" class="read-more" href="https://houtini.com/aiseo/" aria-label="Read more about AI SEO – A Tool to Help You Improve Your Content for AI Search">Read more</a>
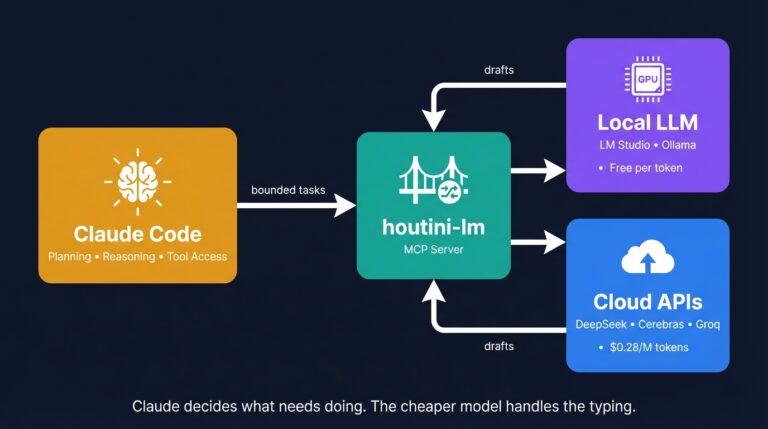
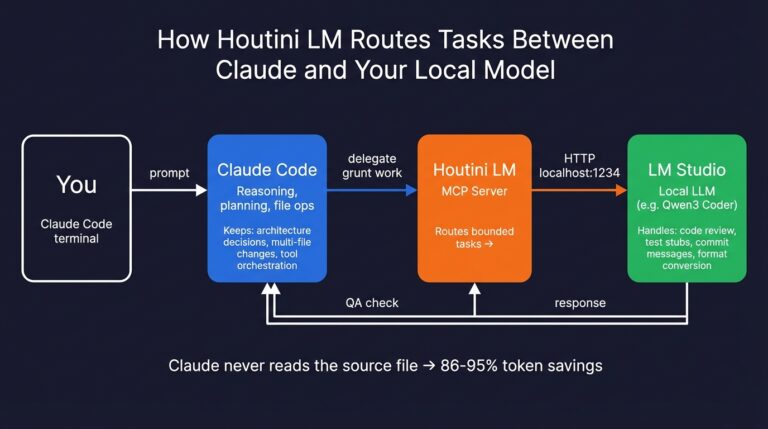
Cut Your Claude Code Token Use by Offloading Work to Cheaper Models with Houtini-LM
I built houtini-lm for people worried that their Anthropic bill might be getting out of hand. I’d leave Claude Code running overnight on big refactors, wake up, and wince at the token count. A huge chunk of that spend was going on tasks any decent coding model handles fine – boilerplate generation, code review, commit … <a title="AI SEO – A Tool to Help You Improve Your Content for AI Search" class="read-more" href="https://houtini.com/aiseo/" aria-label="Read more about AI SEO – A Tool to Help You Improve Your Content for AI Search">Read more</a>
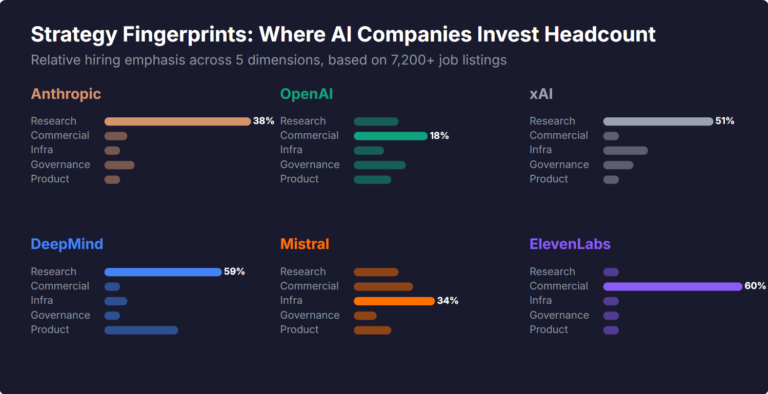
What Skills Are AI Companies Hiring For, and What Do the Jobs Tell Us About Their Strategy?
I pointed YubHub at 7,200+ job listings across the major AI labs and the hiring patterns reveal six completely different strategic bets. Anthropic is all-in on research. OpenAI reads like an enterprise SaaS company. xAI is hiring domain experts to teach Grok finance. Here's what the data shows.

How to Create LinkedIn Carousel Slides with Gemini and Claude
A developer workflow for turning blog posts into LinkedIn carousel slides using Gemini SVG generation, Puppeteer PDF conversion, and a four-line Python merge script. No Canva, no SaaS tools.