
I spend most of my working day in Claude Desktop. Research, writing, data analysis, managing apps I’ve built – it’s all in there. And when you pair it with the right extensions, honestly, it’s astonishing what you can get done.
While Claude is brilliant, it’s the extensions, the MCP servers, that really make it powerful. MCPs (or extensions if you use the Claude Extensions library), allow you to connect Claude to the outside world. Think: writing files, performing searches, fetching data – that type of thing.
So, some housekeeping first. If you’re new to MCP tools in Claude Desktop, I’ve written a starter guide to Claude Desktop here. Should get you up and running pretty quickly.
If you’ve only used the web version of Claude and you wonder what all the fuss is about, let me show you what MCP connections look like:
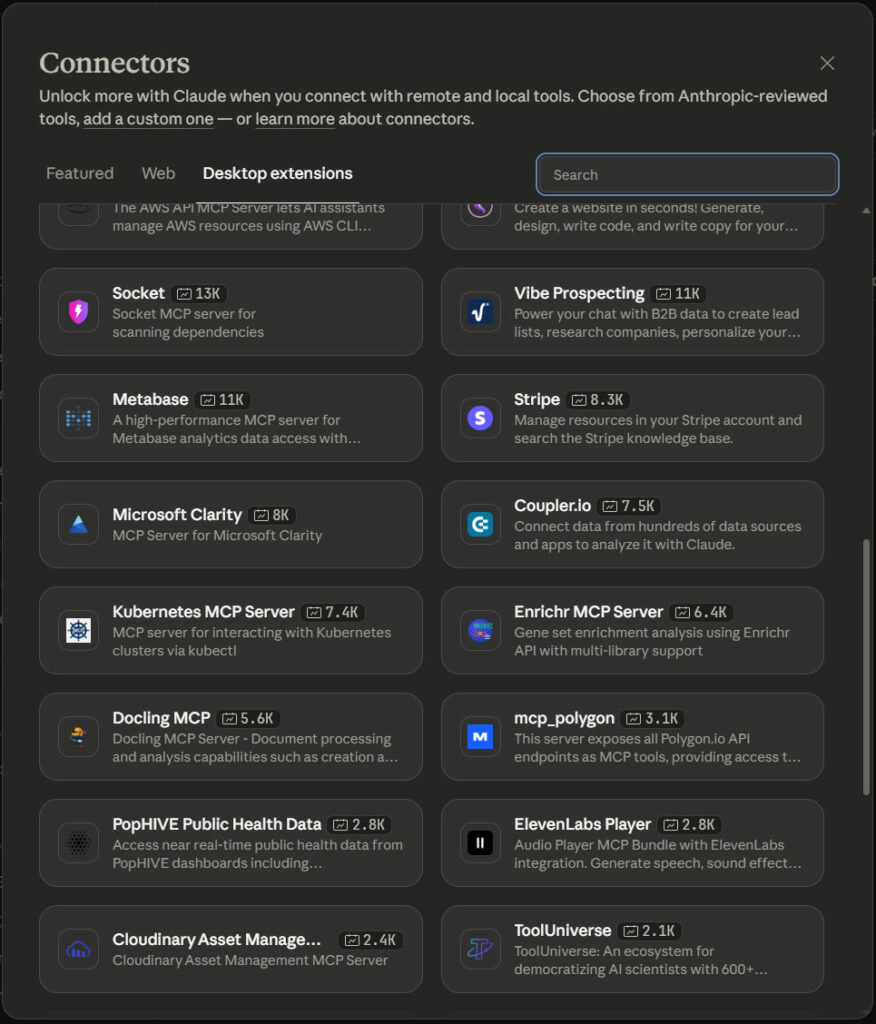
File > Settings > Extensions takes you here
Since I first wrote this article, I’ve added a bunch more MCPs to my daily setup. The ecosystem has grown enormously – thousands of MCP servers on GitHub now, covering everything from weather forecasts to train timetables to Spotify playback control. I’ve updated this guide with the MCPs I actually use every day, and I’ve split the coding-focused ones into a separate best MCPs for Claude Code article.
Quick Navigation
Jump directly to what you’re looking for:
Desktop Commander | Firecrawl | Supadata | Brave Search | Context7 | Chrome DevTools | Google Knowledge Graph | Gemini MCP | YubHub | Better Search Console | DataForSEO | Gmail | Notion | Fun MCPs Worth Knowing About | My Ultimate Desktop Setup
Getting Started
If you’re starting out for the first time, all you need to do is install Node, as I’ve selected extensions available either via the extensions library in Claude Desktop of via NPX (the Node package execution function).
All you need is Node:
You add or edit MCP servers from your claude_config.json. If you’re on Windows, it lives here:
C:\Users\[your username]\AppData\Roaming\Claude\claude_desktop_config.jsonThe file’s JSON, and it looks like this:
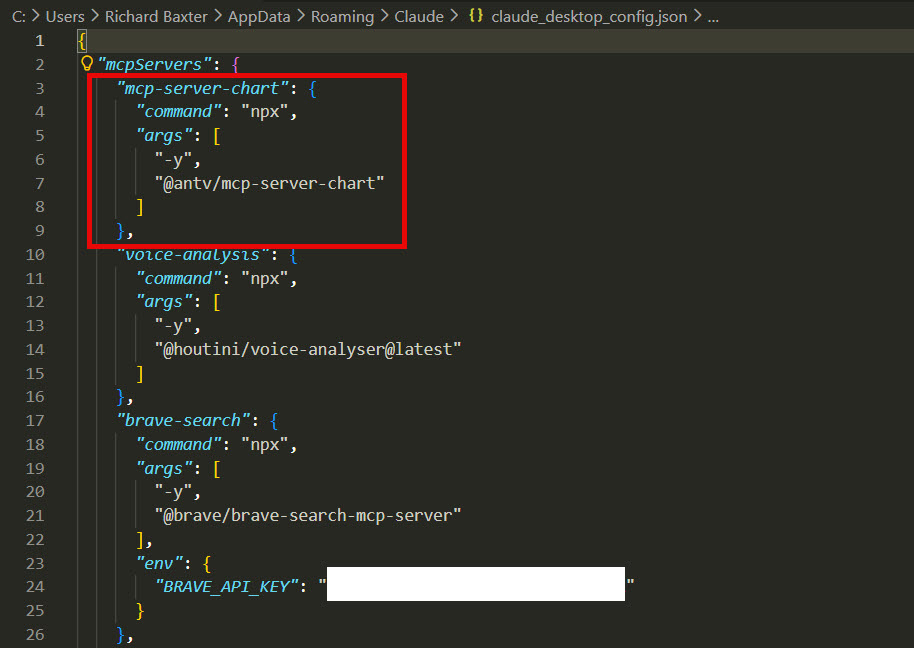
Get the curly braces and commas right. If you mess it up the first time, no drama – re-open the file and fix it.
Anyway, in no particular order – here’s what I actually run.
Desktop Commander
Without Desktop Commander, Claude can’t touch files or run processes outside of its own software. Which is a problem.
It lets Claude read and write files, run terminal commands, manage processes (like kicking off a Node script), and search through your filesystem. Sounds basic, I know, but without it Claude Desktop is just a chatbot. Honestly, you’d be better off staying on the web version at that point. Install Desktop Commander and suddenly it’s a proper assistant – one that can actually interact with your machine.
And if you’re worried about giving Claude file access – don’t be. I’ve been running it for months with zero issues, and you can lock it down to a specific directory in your prompt.
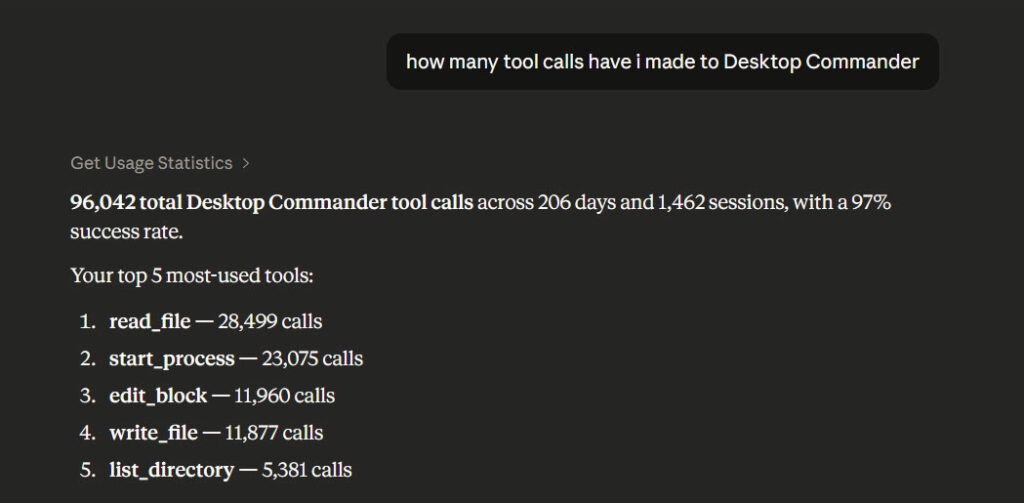
How many tool calls have I made to Desktop Commander?
Oh, and Claude Desktop ships with its own “Code Execution” feature. Turn it off. Desktop Commander does the same job but better, and you get to say which directory Claude works in. The built-in version runs in a sandbox that’s quite restrictive, and worse, Claude basically loses entire files. Not ideal!
I’ve got a dedicated guide to Desktop Commander here.
{
"mcpServers": {
"desktop-commander": {
"command": "npx",
"args": ["-y", "@wonderwhy-er/desktop-commander"]
}
}
}Firecrawl
Firecrawl’s service is part scraper, part AI-powered, ultra configurable retriever of structured data. It’s my go-to data scraper; I use it both as an MCP, in N8N and as the supporting act in the Cloudflare infrastructure I use to keep fresh AI jobs piped through to this very website.
Six main capabilities: scrape (single page), crawl (follow links across a site), map (discover all URLs), search (web search with optional scraping), extract (structured data via LLM), and agent (autonomous browsing). In practice, I mostly use /Scrape through the MCP.
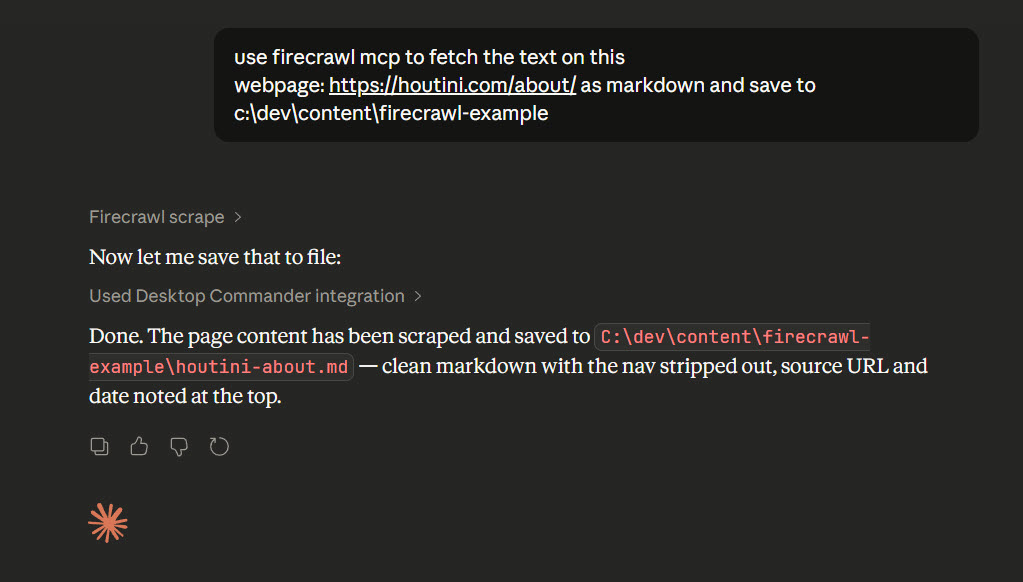
Note: Using Firecrawl combined with Desktop Commander means a background process runs and saves the output, rather than Claude chewing up its context window to try to process the output
There’s a great deal more to Firecrawl than just scraping, and I’ll be demonstrating more use cases soon. For now, I explain here how my job content scraper works, which uses Firecrawl as a JS friendly and very versatile service.
You’ll need an API key from Firecrawl, then set up the MCP like this:
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "your-api-key"
}
}
}
}Supadata
Supadata has become a core part of my content research workflow. Rather than sitting through an entire YouTube video, I grab the transcript with the MCP, then filter out the key research points I need. It handles YouTube, TikTok, Instagram, Twitter (X), and direct file URLs for transcript extraction. Worth installing for that alone, honestly.
Supadata’s transcript extraction pulls actual captions and subtitles from videos across YouTube, TikTok, Instagram, and Twitter (X). It also does site scraping and media metadata extraction on top of that.
The way I use it: find a relevant video, pull the transcript, then ask Claude to extract the specific technical details I’m after. It’s especially good for keeping current with fast-moving topics – science talks, news, product announcements, expert interviews, that sort of thing. Basically, it’s data for data journalism.
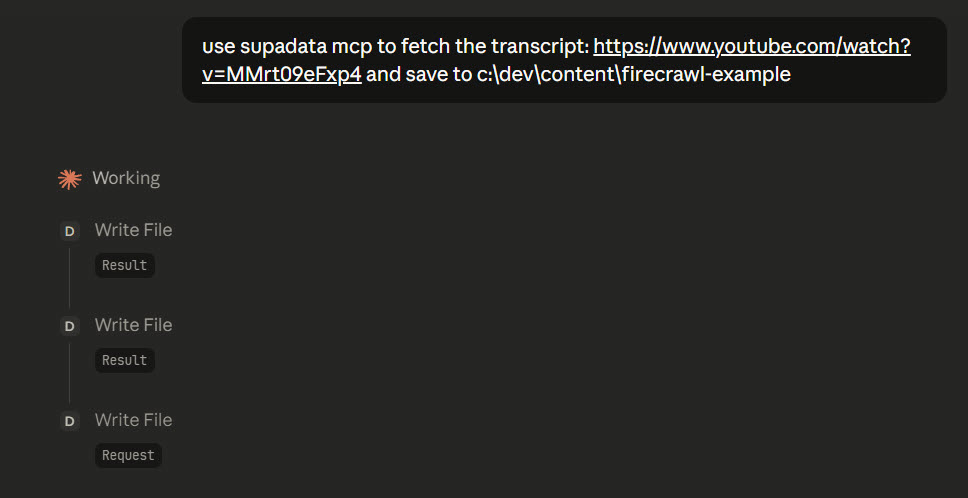
Supadata Transcript Request Prompt
Beyond transcripts, Supadata also does site scraping. It’s much simpler than Firecrawl (for example, it only outputs markdown and has no JS site support), but it’s reliable.
{
"mcpServers": {
"supadata": {
"command": "npx",
"args": ["-y", "@supadata/mcp"],
"env": {
"SUPADATA_API_KEY": "your-api-key"
}
}
}
}Brave Search
Claude Desktop already has built-in web search. So why bother with Brave Search?

Specialisation, basically. Claude’s built-in search is fine for general queries, but Brave Search gives you dedicated endpoints for news, images, videos, and local businesses. If I’m researching what’s been published about a topic in the last 24 hours, the news search with freshness: "pd" is far more targeted than a general web search.
Here’s the MCP config:
{
"mcpServers": {
"brave-search": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-brave-search"],
"env": {
"BRAVE_API_KEY": "your-api-key-here"
}
}
}
}You’ll need a Brave Search API key – there’s a free tier that covers casual use.
Context7
Context7 solves a niche but important problem: Claude’s training data has a cutoff, so if you’re doing research on an app PRD (writing specs, requirements, planning implementation), then Context7, used up front, can save hours of headaches.
My go-to prompt: “Use Context7 to find the latest libraries for this application and consider if the changes may be breaking.” Claude then knows whether the packages it thinks it should be working with are actually current. And honestly, they rarely are – a few months of knowledge cutoff is a lifetime when you’re building things.
{
"mcpServers": {
"context7": {
"command": "npx",
"args": ["-y", "@upstash/context7-mcp"]
}
}
}Chrome DevTools
The Chrome DevTools MCP – this one hands Claude direct control over a Chrome browser. Click elements, fill forms, take screenshots, check the console for JavaScript errors, navigate pages, run JavaScript, monitor network requests, run performance traces. Browser automation through conversation, basically, and the data Claude gets back is brilliant for debugging.
Fair warning though, it can chew through the context window, so be specific with your prompts.
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": ["-y", "chrome-devtools-mcp@latest"]
}
}
}This is Google’s official MCP, not a third-party wrapper. It does collect usage stats by default – stick "--no-usage-statistics" in the args if you’d rather opt out.
More on the Chrome Dev Tools MCP here.
Google Knowledge Graph
The Knowledge Graph MCP is probably the most niche tool on this list, but it fills a specific gap well. It gives Claude access to Google’s structured entity database – the same data that powers those info panels you see on the right side of Google search results.
Google Knowledge Graph MCP (repo here)
I built this one because I kept needing Claude to verify entity information mid-research. Google’s Knowledge Graph has structured data about millions (billions?) of real-world entities – same data behind those knowledge panels in Google Search.
The API’s free tier is generous – 100,000 read calls per day per project. You just need a Google Cloud API key. I’m surprised more developers don’t know about it, to be honest.
This MCP gives Claude (or any MCP client) access to that database.
{
"mcpServers": {
"google-knowledge-graph": {
"command": "npx",
"args": ["-y", "@houtini/google-knowledge-graph-mcp"],
"env": {
"GOOGLE_KNOWLEDGE_GRAPH_API_KEY": "your-api-key"
}
}
}
}Gemini MCP
Saving the best till last – my very own Gemini MCP. I genuinely don’t think people realise yet how useful it is to have Claude connected to grounded Gemini results.
When Claude and I get stuck on a bug, I tell it to check with Gemini. For content research, fact-checking, verifying data – I lean on it constantly.
But what most people don’t clock about the Gemini MCP – it generates images. Not just chat. I use it for diagrams, architecture visuals, article illustrations, all without leaving Claude Desktop. This one took a single prompt:

Made with the Gemini MCP inside Claude Desktop. One prompt, no Photoshop, no Midjourney.
It does deep research too (multi-step, grounded web searches that get synthesised into reports), video generation, SVG creation, image editing. I’ve written a full guide to the Gemini MCP here.
{
"mcpServers": {
"gemini": {
"command": "npx",
"args": ["@houtini/gemini-mcp"],
"env": {
"GEMINI_API_KEY": "your-api-key-here"
}
}
}
}You’ll need a Gemini API key – grab one from Google AI Studio.
YubHub
I built this one as well. YubHub is a saas that produce employer job feeds and employment insights from teh world’s top comapnies. It has an MCP that manages the app – it’s the engine behind the AI jobs board on this site. I’m including it here because it’s a good example of what MCPs are actually for: connecting Claude to an app you’ve built and managing it through conversation.
I say “show me the YubHub dashboard” and Claude pulls feed stats, job counts, error rates. I trigger feed runs, check which feeds are failing, debug issues, all without opening a browser. It basically turns Claude Desktop into a control panel for an application that would otherwise need its own admin UI.
If you’re building any kind of data pipeline or content system, building an MCP for it is worth the effort. The pattern is dead simple – expose your CRUD operations as MCP tools and Claude can manage the whole thing.
{
"mcpServers": {
"yubhub": {
"command": "npx",
"args": ["@houtini/yubhub"],
"env": {
"YUBHUB_API_KEY": "your-api-key"
}
}
}
}Better Search Console
Google Search Console’s API caps out at 1,000 rows per request. A couple of queries and you’ve burned through your context window. I got fed up with that, so I built Better Search Console – it syncs your GSC data into a local SQLite database and lets Claude query it with SQL.
Night and day difference. Instead of Claude fetching 1,000 rows and trying to hold them in context, it runs targeted SQL queries against the local database, gets exactly what it needs. I check it daily. Which articles are climbing, which are dropping, where the keyword gaps are, whether anything’s broken technically.
{
"mcpServers": {
"better-search-console": {
"command": "npx",
"args": ["@houtini/better-search-console"],
"env": {
"GOOGLE_SERVICE_ACCOUNT_KEY": "path-to-your-service-account.json"
}
}
}
}There’s a full setup guide here.
DataForSEO
DataForSEO gives Claude access to SERP data, keyword volumes, Google Trends, domain analytics, YouTube search results. Not cheap (API credits), but for content research it’s worth every penny. I ask Claude to check what’s ranking for a keyword, pull search volumes, analyse a competitor’s tech stack – all without leaving the conversation.
My most common prompt: “Check what’s ranking for [keyword] in the UK and tell me what angle the top results are taking.” Claude pulls the SERP, scrapes the top 3 with Firecrawl, gives me a competitive analysis in about 30 seconds. Genuinely useful.
There’s a detailed guide to getting DataForSEO working with Claude Desktop here, and a deeper look at the DataForSEO MCP here.
{
"mcpServers": {
"dataforseo": {
"command": "npx",
"args": ["-y", "@nicholasoxford/dataforseo-mcp"],
"env": {
"DATAFORSEO_LOGIN": "your-login",
"DATAFORSEO_PASSWORD": "your-password"
}
}
}
}Gmail
I was sceptical about giving Claude access to my email. Properly sceptical. But the Gmail MCP turned out to be one of the more practical MCPs I run. Mostly for search and triage – “find the last email from [person] about [topic]” or “summarise the thread about the contract renewal.”
Don’t let Claude write your emails (please). But pulling context from your inbox while you’re working on something related? That’s where it shines. I’m writing a brief for a client project, I tell Claude to grab the original scope email and pull the key bits into my working document. Done in seconds.
{
"mcpServers": {
"gmail": {
"command": "npx",
"args": ["-y", "@gongrzhe/server-gmail-autoauth-mcp"]
}
}
}Notion
Notion recently launched their official MCP server, and it’s properly good. If you use Notion for project management, task tracking, or as a knowledge base (half the internet does), this connects Claude directly to your workspace.
I use it to pull context from planning docs without copy-pasting between tabs. “What’s the current status of the content calendar?” – Claude reads the Notion database, gives me a summary. Works with pages, databases, comments, search. Pretty much everything.
Setup is straightforward – Notion host the server themselves:
{
"mcpServers": {
"notion": {
"command": "npx",
"args": ["-y", "@notionhq/notion-mcp-server"],
"env": {
"OPENAPI_MCP_HEADERS": "{\"Authorization\": \"Bearer your-notion-integration-token\", \"Notion-Version\": \"2022-06-28\"}"
}
}
}
}Fun MCPs Worth Knowing About
So the MCP ecosystem has properly exploded. And beyond the productivity stuff above, some of the fun ones are worth a look:
Weather – SaintDoresh/Weather-MCP-ClaudeDesktop hooks into the OpenWeatherMap API. Sounds gimmicky, right? But I ask Claude “should I cycle to the office tomorrow?” and it gives me an actual answer based on forecast data. Weirdly useful.
Public Transport – mirodn/mcp-server-public-transport covers train and bus schedules across Europe (UK, Switzerland, Norway, Belgium). Being able to ask “what time’s the next train from [station]?” mid-conversation is handy.
Spotify – Yes, there’s a Spotify MCP. Control playback, queue tracks, search your library from Claude. Essential? No. Fun? Absolutely.
The awesome-mcp-servers list – wong2/awesome-mcp-servers on GitHub is the community-maintained directory. Thousands of servers, every category you can think of. Have a browse.
My Ultimate Desktop Setup
If someone asked me “just tell me what to install,” this is what I’d say.
The essentials (install these first):
- Desktop Commander – without this, Claude Desktop is just a chatbot
- Firecrawl – web scraping and data extraction
- Brave Search – targeted web, news, image, video search
- Gemini MCP – grounded search, fact-checking, image generation
For research and content work:
- Supadata – YouTube transcripts, video research
- Context7 – current library documentation
- DataForSEO – keyword and SERP data
- Better Search Console – SEO analytics
For managing your work:
- Gmail – email search and context pulling
- Notion – project management, knowledge base
- YubHub (or your own app MCP) – control your tools through conversation
For debugging:
- Chrome DevTools – browser automation and debugging
- Google Knowledge Graph – entity verification
Thirteen MCPs. Sounds like a lot, but they don’t all run at once – Claude only activates the ones it needs for your current prompt. Context window cost is minimal.
Looking for Claude Code MCPs?
If you’re using Claude Code (the terminal-based coding agent), the MCP setup is different. Claude Code has its own file access, search, and editing tools built in, so you don’t need Desktop Commander. The MCPs that work best in Claude Code are things like GitHub for PR management, Sequential Thinking for complex architecture decisions, Postgres and SQLite for database access, and Docker MCP Toolkit for running servers in containers.
Context7 and Gemini MCP work in both Desktop and Code – I use them everywhere.
I’ll be publishing a dedicated best MCPs for Claude Code article soon.
Related Articles

How to Make Images with Claude and (our) Gemini MCP
My latest version of @houtini/gemini-mcp (Gemini MCP) now generates images, video, SVG and html mockups in the Claude Desktop UI with the latest version of MCP apps. But – in case you missed, you can generate images, svgs and video from claude. Just with a Google AI studio API key. Here’s how: Quick Navigation Jump … <a title="The Best MCPs for Claude Desktop (And How I Use Them)" class="read-more" href="https://houtini.com/the-best-mcps-for-claude-desktop/" aria-label="Read more about The Best MCPs for Claude Desktop (And How I Use Them)">Read more</a>

Yet Another Memory MCP? That’s Not the Memory You’re Looking For
I was considering building my own memory system for Claude Code after some early, failed affairs with memory MCPs. In therapy we’re encouraged to think about how we think. A discussion about metacognition in a completely unrelated world sparked an idea in my working one. The Claude Code ecosystem is flooded with memory solutions. Claude-Mem, … <a title="The Best MCPs for Claude Desktop (And How I Use Them)" class="read-more" href="https://houtini.com/the-best-mcps-for-claude-desktop/" aria-label="Read more about The Best MCPs for Claude Desktop (And How I Use Them)">Read more</a>

The Best MCPs for Content Marketing (Research, Publish, Measure)
Most front line content marketing workflow follows the same loop. Find something worth writing about, dig into what’s already ranking on your site, update or write it, run it through SEO checks, shove it into WordPress, then wait to see if anyone reads it. Just six months ago that loop was tedious tab-switching and copy-pasting. … <a title="The Best MCPs for Claude Desktop (And How I Use Them)" class="read-more" href="https://houtini.com/the-best-mcps-for-claude-desktop/" aria-label="Read more about The Best MCPs for Claude Desktop (And How I Use Them)">Read more</a>
How to Set Up LM Studio: Running AI Models on Your Own Hardware
How does anyone end up running their own AI models locally? For me, it started because of a deep interest in GPUs and powerful computers. I’ve got a machine on my network called “hopper” with six NVIDIA GPUs and 256GB of RAM, and I’d been using it for various tasks already, so the idea of … <a title="The Best MCPs for Claude Desktop (And How I Use Them)" class="read-more" href="https://houtini.com/the-best-mcps-for-claude-desktop/" aria-label="Read more about The Best MCPs for Claude Desktop (And How I Use Them)">Read more</a>
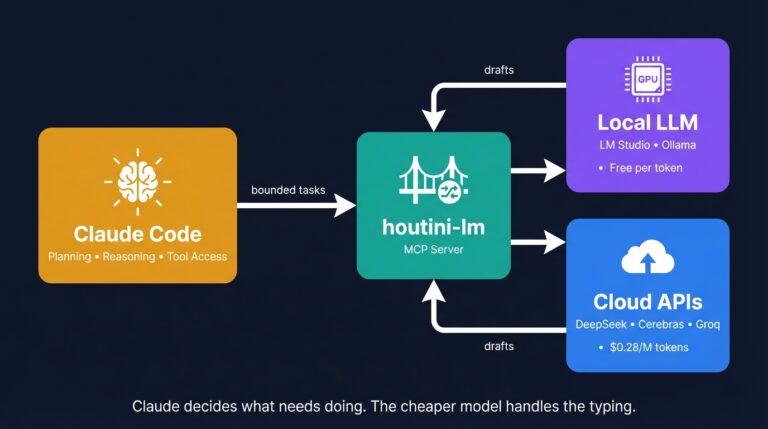
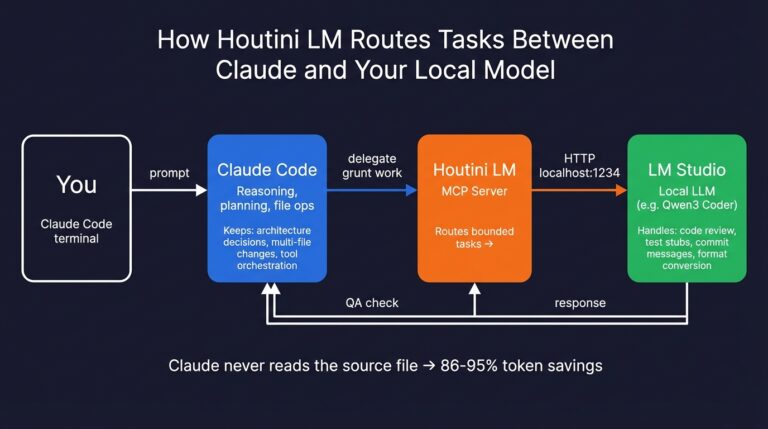
Cut Your Claude Code Token Use by Offloading Work to Cheaper Models with Houtini-LM
I built houtini-lm for people worried that their Anthropic bill might be getting out of hand. I’d leave Claude Code running overnight on big refactors, wake up, and wince at the token count. A huge chunk of that spend was going on tasks any decent coding model handles fine – boilerplate generation, code review, commit … <a title="The Best MCPs for Claude Desktop (And How I Use Them)" class="read-more" href="https://houtini.com/the-best-mcps-for-claude-desktop/" aria-label="Read more about The Best MCPs for Claude Desktop (And How I Use Them)">Read more</a>
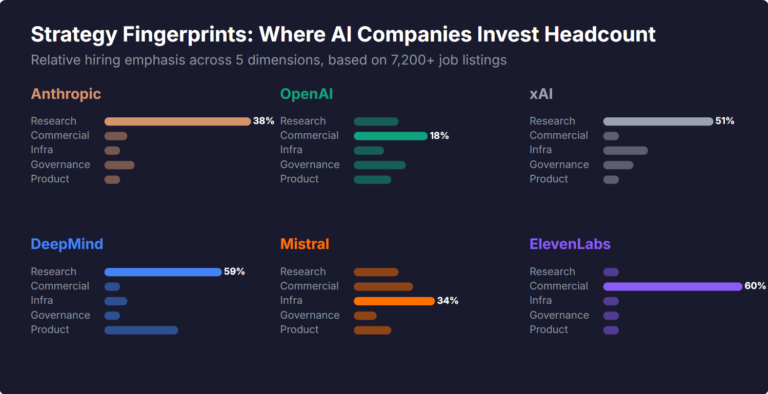
What Skills Are AI Companies Hiring For, and What Do the Jobs Tell Us About Their Strategy?
I pointed YubHub at 7,200+ job listings across the major AI labs and the hiring patterns reveal six completely different strategic bets. Anthropic is all-in on research. OpenAI reads like an enterprise SaaS company. xAI is hiring domain experts to teach Grok finance. Here's what the data shows.