
About eighteen months ago I bought a used RTX 3090, mostly because I was tired of paying API costs every time I wanted to experiment with a model. I’d pull a 13B model, chat with it, try a bigger one, hit the VRAM wall, and immediately start thinking about a second card. The 3090 turned into a Threadripper 5990x workstation with six NVIDIA Ada GPUs and 104GB of VRAM – it sits in my office, runs all day, and i’ve even built an MCP for Claude Code to work with my Local LLM (running LM Studio).
In today’s article, I’m going to talk about the hardware mistakes and lucky finds, from a £400 GPU shoved into my work PC to my multi-GPU rigs handling large parameter models very respectably.
Quick Navigation
Jump directly to what you’re looking for:
VRAM & Quantization |
Hardware Secrets |
Budget (Under £800) |
Mid-Range (£800-£3,000) |
Premium (£3,000+) |
Software Stack |
Comparison Table
The Number That Matters
Something I’ve learned building these rigs: when it comes to PC workstations, VRAM on the GPU decides everything. Not clock speed, not CUDA cores, not the number NVIDIA puts on the box. If a model fits in your GPU’s memory, it runs fast enough. If it doesn’t fit, you’re at two tokens per second becuase your machine will most likely attempt to fit the rest of teh model in your main RAM – it still works but it’s slooow!
People overcomplicate this, but we’re in beginner mode so let’s break it down. Every parameter in your model has to sit in memory somewhere – you can’t get around that. At full precision (FP16), one parameter costs you 2 bytes. A 70 billion parameter model at full precision is 140GB. No consumer GPU on the planet has that kind of VRAM ,yet. Even 3 of those 48gb modified “4090D” cards you see on eBay would probably melt.
Quantisation fixes this. Compress those billions of parameters down to 4-bit (Q4_K_M is the format you’ll see everywhere) and each one drops to roughly half a byte. That 70B model goes from 140GB to about 40GB – two used RTX 3090s with room for context window overhead. I’ve been running Qwen 3 Coder Next at Q6 quantisation on my own rig for a couple of months now and can’t feel any quality difference from full precision on the tasks I throw at it. It’s really pretty good – and I will be writing about getting it setup soon.
Quick VRAM Guide
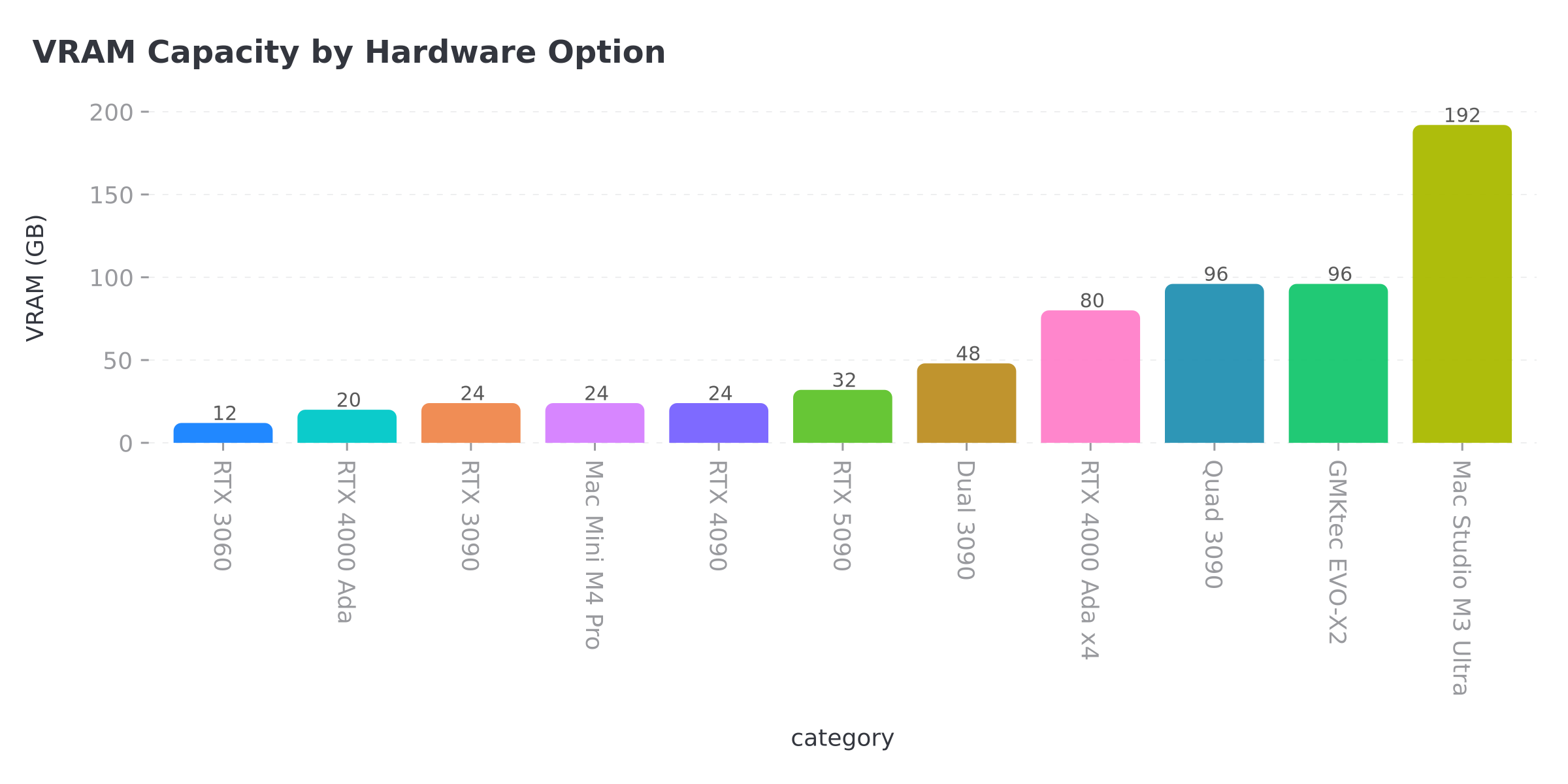
So what sort of size model can run on your VRAM? Betware – 3080’s have 10gb versions so watch out if you’re buying 2nd hand on eBay.
| Model Size | At Q4 (4-bit) | At Q8 (8-bit) | Good GPU Fit |
|---|---|---|---|
| 7B | 6-8 GB | 10-12 GB | RTX 3060 12GB |
| 13-14B | 10-12 GB | 16-18 GB | RTX 3060 12GB, 4060 Ti 16GB |
| 34B | 20-24 GB | 30+ GB | RTX 3090 or 4090 (24GB) |
| 70B | ~40 GB | ~75 GB | Dual 3090s, Mac Studio, or RTX 5090 |
| 100B+ | 60-70 GB | 100+ GB | Quad 3090s, M3 Ultra 192GB |
Don’t forget KV cache on top of this – KV Cache it stores your conversation state and grows with context length. At 32k tokens, budget for another 2-4GB, which caught me out the first time I tried to squeeze a 34B onto a 24GB card.
Local LLM Hardware Secrets
Here are three bits of hardware wisdom I’ve had to learn the expensive way.
One Fast Card Beats Two Slow Ones
Tempting maths: two RTX 3060 12GB cards give you 24GB total. Same VRAM as a single 3090. Same capacity, completely different speed. This is a big mistake on my part – I bought an array of bargain ADA generation RTX 4000s and 4500s – the mixture of the cards and the volume of them was a mistake. It runs but I think i’m losing at least 20% of teh performance simply becuase of all the PCI lanes in play.
Digital Spaceport did the numbers. A single 3090 hits 28 tokens per second on Gemma 3 27B at Q4. The dual 3060 setup? Six. On the exact same model. Splitting a model across GPUs over PCIe – sharding, they call it – kills throughput because the cards spend more time talking to each other than doing inference. I really, really wish I understood this before I sold my 3090’s from my GPU mining days.
So when does multi-GPU work? When the model needs both cards anyway. Two 3090s running a 70B model that requires 48GB of VRAM is fine – fifteen to twenty tok/s with NVLink. But don’t buy two cheap cards hoping they’ll match one expensive one. They won’t. Don;t mix generations of cards, don’t mix VRAM numbers – and most consuder “gaming” montherboards dont support full 16 channel PCI on more than 1 of the PCI slots. Just so you know. Simple is actually the best apporach!
Apparently, NVLink Changes things for Multi-GPU Fine Tuning
Something I genuinely didn’t expect when I added my second GPU: the connection between the cards ends up mattering almost as much as the cards themselves in specific use cases. What NVLink does is give the GPUs their own private highway – 112.5 GB/s bidirectional. Compare that with regular PCIe 4.0 x8, which tops out around 16 GB/s. About seven times slower, and you absolutely notice it in practice.
The caveat: NVlink is better for fine tuning performance, not for inference (chat!) – oh well.
Apple Silicon: Capacity Over Speed
A Mac Studio M3 Ultra with 192GB of unified memory can load models that would need four discrete NVIDIA GPUs on a PC. All that RAM is GPU-accessible. No PCIe bottleneck, no sharding penalty. Near-silent, too, which matters if (like me) you’re working in the same room as the hardware.
Speed-wise, NVIDIA is quicker – about 2-3x on models that fit in its VRAM. A dual 3090 PC does 15-20 tok/s on 70B; the M3 Ultra manages 8-12 tok/s on the same model. Where the Mac pulls ahead is models above 100B parameters that the PC can’t touch without a quad-GPU build, and frankly, for research tasks where you’re running huge models rather than chatting interactively, it makes more sense than people give it credit for.
Budget: Under £800
RTX 3060 12GB
The cheapest way into serious local AI. Twelve gigabytes of VRAM at 170W TDP, running 7B models at Q8 or 13B models at Q4 – Llama 3, Mistral, Phi-3, all the capable smaller models that have come out this past year.
Why this over a newer RTX 4060? Because the 4060 only ships with 8GB of VRAM, and for AI work, 12GB from an older generation beats 8GB from a newer one every single time – pretty much consensus in the local LLM community at this point. Pick one up for about £200 on Amazon, pair it with a used HP Z440 workstation off eBay (about £100) and you’ve got a complete AI rig for under £350. System idles at around 65 watts.
RTX 3090 24GB (Used/Renewed)
Yeah, it’s two generations old. The local AI community collectively shrugged at that ages ago and kept buying them.
Twenty-four gigabytes of GDDR6X handles 34B models at Q4 or 70B at tight quantisation. I ran one of these for about a year before the Threadripper build happened, and looking back I’m slightly embarrassed at how long I underestimated what a single 24GB card could handle. Community benchmarks from Digital Spaceport show 28-36 tok/s on 14B models, 28 tok/s on Gemma 3 27B Q4. Nothing under a grand comes close to that combination of capacity and speed – and it’s got NVLink support for when you inevitably want to add a second one.
Renewed cards run £650-800 on Amazon. Most sellers give you about 90 days of warranty. Bit of a gamble, but I’ve not heard of widespread failure rates from the AI community. If you’re planning multi-GPU later, look for blower-style cards – they exhaust heat out the back instead of dumping it onto the card above. The 350W TDP per card adds up fast when you’ve got two of them in the same case.
Mid-Range: £800 – £3,000
GMKtec EVO-X2 (AMD Ryzen AI Max+ 395)
The surprise entry. A mini PC with 128GB of LPDDR5X unified memory, 96GB of which is allocatable to the integrated GPU. Runs 70B models. No discrete graphics card needed. Fits on a shelf. Near-silent.
Speed won’t match a 3090, mind you – somewhere around 10-15 tok/s on 27B models from what I’ve seen. For an always-on inference box that handles 70B from under your desk without waking the house though, I haven’t found anything else in this bracket. Around £2,000-2,500 on Amazon.
Mac Mini M4 Pro (24GB)
Apple’s cheapest route into unified memory for AI work. Twenty-four gig of unified memory, which handles 13-14B models nicely through MLX. Slower on raw tok/s than a 3090, but the software side is painless – Ollama runs natively, no CUDA drivers to wrestle with. £1,399 on Amazon.
Not going to touch 70B, not remotely. But for 7-14B work – coding assistants, summarisation, local chatbots – genuinely lovely quiet machine that does exactly what you’d want. If you’re on macOS already and want to dip a toe into local inference, this is probably where I’d point you first.
RTX 4000 Ada (Workstation, 20GB)
I run these in my own rig and they’ve been brilliant. Single-slot form factor at 130W per card, twenty gig of VRAM each. Stick four of them in a standard workstation case and you’re sitting on 80GB total at 520W combined – more than enough for 70B models at Q5 with headroom left over for context windows.
I’ve got six in my Threadripper 5990x (mixed with RTX 4500 Adas) for 104GB total. Quiet enough to sit in my office all day, which was the main engineering constraint because I’m working next to it eight hours a day. The whole system pulls about 800W under full inference load – sounds like a lot until you compare it with a quad 3090 setup drawing 1,400W. Raw tok/s per card is lower than gaming GPUs, but the density and power efficiency are what sold me for a machine that runs continuously. About £1,150 each on Amazon.
Dual RTX 3090 Build
The prosumer sweet spot for people who want 70B models on NVIDIA hardware. Two 3090s together give you 48GB of total VRAM. Bridge them with NVLink and you’re looking at 15-20 tok/s on 70B Q4. Skip the bridge and it drops to 10-14 tok/s, which sounds bad until you actually try it – still plenty fast enough to hold a conversation with a model.
Build essentials: the pair of cards will set you back £1,300-1,500 used. The PSU situation gets interesting because each card wants 350W under load, so budget for a 1,200-1,600W unit. For the platform, Threadripper or HEDT gives you full x16/x16 PCIe bandwidth – consumer boards like Z790 or X670E split to x8/x8, which works but costs some throughput. An NVLink bridge runs about £40-60 used. Whole thing comes in at £1,800-2,200 depending on your platform choice, and no, nobody sells this as a pre-built – you’re getting your hands dirty.
Premium: £3,000+
RTX 5090 (32GB)
The biggest single card you can walk into a shop and buy. Thirty-two gigabytes of GDDR7, 512-bit bus, Blackwell architecture – and for the first time, a quantised 70B model actually fits on one card. No sharding, no NVLink, no dual-GPU headaches. One slot, done.
No Amazon listing at time of writing – stock’s been erratic since launch and GDDR7 supply has pushed street prices to £2,400-3,000, well above the £1,799 MSRP. Check Scan, Overclockers, or NVIDIA directly. The 575W TDP is substantial, too – make sure your PSU can handle it before you get excited and order one.
RTX 4090 (24GB)
Still the fastest card with 24GB of VRAM, and by a decent margin over the 3090 on raw tok/s. Same VRAM ceiling though, and that’s the catch – twenty-four gig is twenty-four gig regardless of what you paid. Buying new? Get this one. Buying used? The 3090 at roughly half the price gives you the same model capacity – which is the metric that matters for local AI. £1,600-2,000 on Amazon.
Mac Studio M4 Max / M3 Ultra
For running the biggest models money can buy in a desktop form factor. The M4 Max with 128GB (from £3,999) runs 70B models at high quantisation with room for long context windows. The M3 Ultra at 192GB (from £5,999) remains the capacity flagship – Apple hasn’t shipped an M4 Ultra yet. A hundred and ninety-two gigabytes of unified memory handles 100B+ parameter models that would need a quad-GPU PC build to match.
Both from apple.com only. Same trade-off as the Mac Mini: slower tok/s than NVIDIA on models that fit in NVIDIA VRAM, but a capacity ceiling nothing else touches in a quiet box.
Quad RTX 3090 Build (AM4/AM5)
Digital Spaceport validated this build: four RTX 3090s on an AM4 B550 motherboard. Ninety-six gigabytes of VRAM. We’re talking 100-180 tok/s on 12-20B models, which is absurd throughput. Price per GB of VRAM works out to roughly £30/GB – the cheapest path to serious capacity if you don’t mind some noise.
The PSU needs to be a 2,000W unit minimum and you’ll want a case with serious airflow (or an open-air test bench, which is what most people building these seem to end up with). Fair warning: your partner will comment on the noise. You’ve basically built a small datacenter that happens to live under your desk. Budget: £3,000-3,500 for GPUs plus platform.
Software Stack
Buying the hardware’s actually the easy bit – it’s the software stack where people tend to get stuck.
Ollama – installed it the day I got my first 3090, and it’s still the one I’d tell anyone to start with. The whole workflow is ollama pull llama3:70b and then you’re chatting. Quantisation handled for you, works on everything. Benchmarks I’ve looked at suggest you lose maybe 10-30% on raw throughput versus running llama.cpp bare – which sounds bad until you remember Ollama had you running models in five minutes flat while you’d still be reading llama.cpp compile flags.
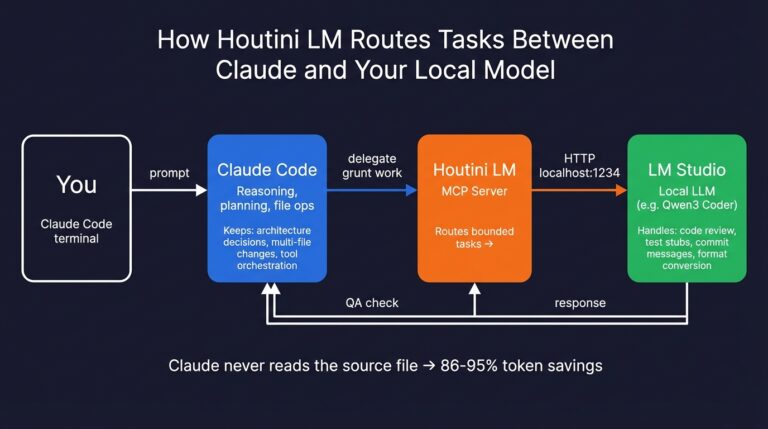
LM Studio has the best GUI experience I’ve found for local models. Built-in model browser, chat-with-your-files (that’s RAG), no terminal needed. Perfect if terminals make you nervous. I use LM Studio on my inference rig alongside the houtini-lm MCP server I built for offloading work from Claude Code to cheaper models.
llama.cpp is the speed baseline that everything else gets measured against. More config, more control, faster output. Serious multi-GPU setups tend to run this directly rather than going through Ollama’s wrapper.
text-generation-webui – oobabooga’s project, and honestly the one that taught me most about how inference actually works. You pick between ExLlamaV2 (fastest GPU-only loader) or llama.cpp (flexible CPU offloading) depending on your hardware situation. Learning curve is real, took me a solid weekend to get comfortable, but once you’re past that you can tune everything and understand why your settings matter.
GGUF vs EXL2
Two model formats worth knowing about. GGUF runs everywhere – Macs, mixed CPU/GPU setups, systems where the model doesn’t quite fit in VRAM. Universal format. EXL2 is NVIDIA GPU-only but faster when the model fits entirely in VRAM.
On Apple Silicon: GGUF via MLX or llama.cpp. Got enough NVIDIA VRAM? EXL2 for best speed. Not sure which? GGUF. It always works.
Hardware Compared
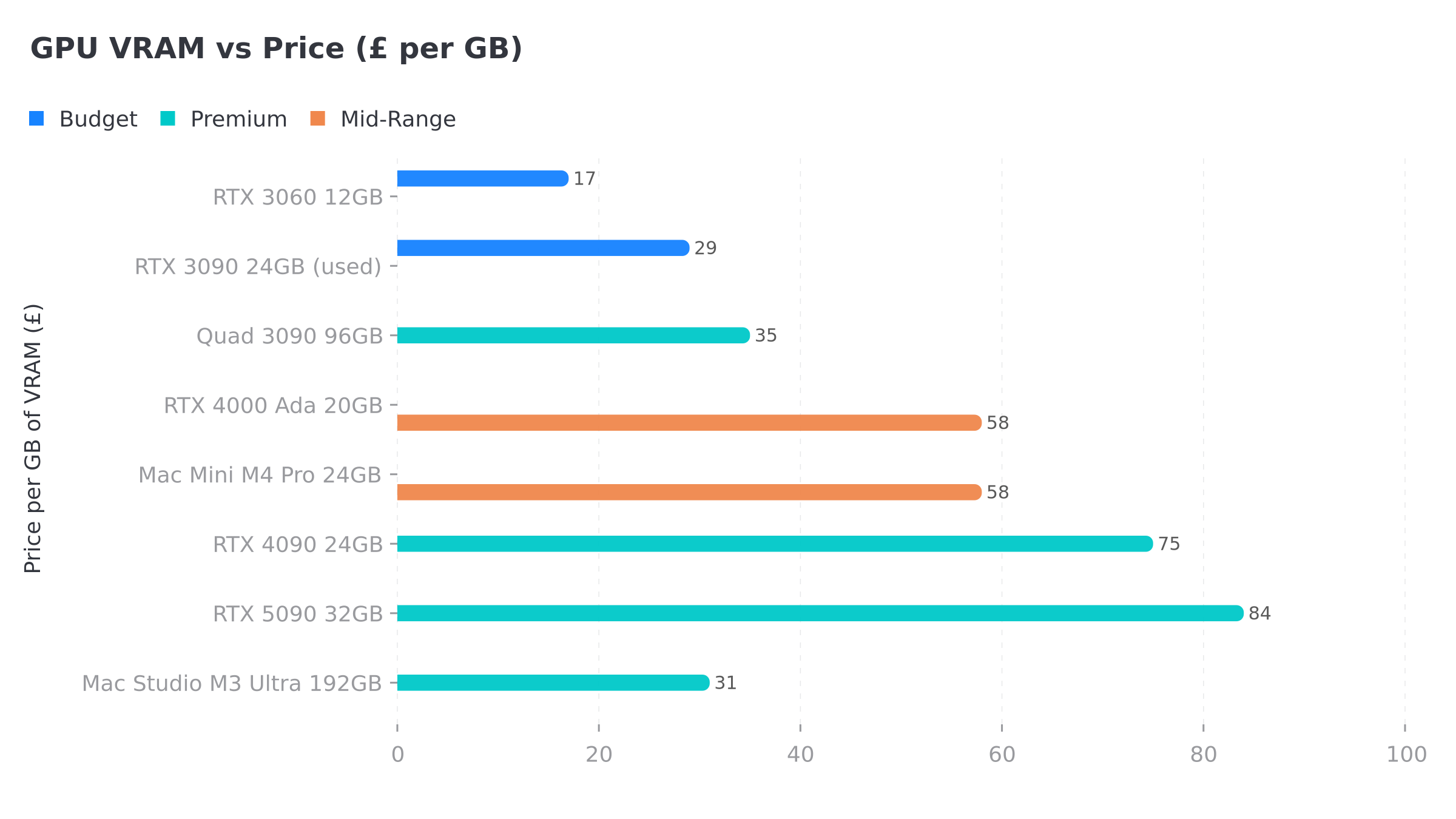
| Hardware | VRAM | Price (GBP) | tok/s (14B) | tok/s (27B+) | Best For |
|---|---|---|---|---|---|
| RTX 3060 12GB | 12GB | ~200 | ~17-20 | – | Budget entry, 7-13B models |
| RTX 3090 (used) | 24GB | 650-800 | 28-36 | ~28 | Best value for serious work |
| Mac Mini M4 Pro | 24GB unified | 1,399 | ~15-20 est | – | Silent macOS, 13B models |
| GMKtec EVO-X2 | 96GB alloc | ~2,000-2,500 | ~15-20 est | ~10-15 est | 70B in a mini PC, silent |
| RTX 4000 Ada | 20GB | 1,150 | ~20-25 est | – | Multi-GPU builds, low power |
| Dual 3090 (NVLink) | 48GB | 1,800-2,200 | 30+ | 15-20 | 70B models, prosumer |
| RTX 4090 | 24GB | 1,600-2,000 | ~40-50 est | ~35 est | Fastest 24GB option |
| RTX 5090 | 32GB | 2,400-3,000 | ~50+ est | ~40 est | Single-GPU 70B, no sharding |
| Mac Studio M3 Ultra | 192GB unified | 5,999+ | ~10-15 est | ~8-12 est | 100B+ models, nothing else can |
| Quad 3090 | 96GB | 3,000-3,500 | 100-180 | 26+ | Maximum VRAM on a budget |
Benchmarked figures from Digital Spaceport. Estimates marked ‘est’ from Gemini research and community reports.
What I’d Actually Buy
Had someone asked me this question two years ago I’d have said “whatever has the most VRAM under a grand.” My answer hasn’t really changed. Under £800, a used RTX 3090 is still the obvious play. Twenty-four gig of VRAM for under £800, NVLink ready for the inevitable second card, and enough capacity to run every model up to 34B at decent quantisation. Exactly where I started, and knowing what I know now, I’d make the same call.
Between £800 and £3,000, the right choice really comes down to what bothers you most about your current setup. Noise? The GMKtec EVO-X2 runs 70B from a box you can hide on a shelf. Already on macOS and working with smaller models? Mac Mini M4 Pro. Interested in going down the same rabbit hole I went down? RTX 4000 Ada cards in a Threadripper workstation – quiet, dense, and the power draw won’t terrify you.
Above £3,000, the RTX 5090 is the obvious pick if you can find one at a sane price – one card, one slot, 70B without any of the multi-GPU headaches. For maximum capacity on a budget, the quad 3090 build on AM4 gets you 96GB of VRAM at about £30 per gigabyte. Ugly, loud, and you’d struggle to find anything with that much VRAM for less money.
Buy the most VRAM you can afford. Pretty much everything else is secondary.
Related Posts
Using a Local LLM to Audit Your Codebase – What Qwen3 Coder Next Catches (and Misses)
I run a local copy of Qwen3 Coder Next on a machine under my desk. It pinned down a race condition in my production code that I’d missed. It also told me, with complete confidence, that crypto.randomUUID() doesn’t work in Cloudflare Workers. It does. That tension – real bugs mixed with confident nonsense – is … <a title="Best AI PCs for Running Local LLMs" class="read-more" href="https://houtini.com/best-pcs-for-local-ai-tested-specs-for-running-llms-without-the-cloud/" aria-label="Read more about Best AI PCs for Running Local LLMs">Read more</a>
How to Make SVGs with Claude and Gemini MCP
SVG is having a moment. Over 63% of websites use it, developers are obsessed with keeping files lean and human-readable, and the community has turned against bloated AI-generated “node soup” that looks fine but falls apart the moment you try to edit it. The @houtini/gemini-mcp generate_svg tool takes a different approach – Gemini writes the … <a title="Best AI PCs for Running Local LLMs" class="read-more" href="https://houtini.com/best-pcs-for-local-ai-tested-specs-for-running-llms-without-the-cloud/" aria-label="Read more about Best AI PCs for Running Local LLMs">Read more</a>

How to Make Images with Claude and (our) Gemini MCP
My latest version of @houtini/gemini-mcp (Gemini MCP) now generates images, video, SVG and html mockups in the Claude Desktop UI with the latest version of MCP apps. But – in case you missed, you can generate images, svgs and video from claude. Just with a Google AI studio API key. Here’s how: Quick Navigation Jump … <a title="Best AI PCs for Running Local LLMs" class="read-more" href="https://houtini.com/best-pcs-for-local-ai-tested-specs-for-running-llms-without-the-cloud/" aria-label="Read more about Best AI PCs for Running Local LLMs">Read more</a>

Yet Another Memory MCP? That’s Not the Memory You’re Looking For
I was considering building my own memory system for Claude Code after some early, failed affairs with memory MCPs. In therapy we’re encouraged to think about how we think. A discussion about metacognition in a completely unrelated world sparked an idea in my working one. The Claude Code ecosystem is flooded with memory solutions. Claude-Mem, … <a title="Best AI PCs for Running Local LLMs" class="read-more" href="https://houtini.com/best-pcs-for-local-ai-tested-specs-for-running-llms-without-the-cloud/" aria-label="Read more about Best AI PCs for Running Local LLMs">Read more</a>

The Best MCPs for Content Marketing (Research, Publish, Measure)
Most front line content marketing workflow follows the same loop. Find something worth writing about, dig into what’s already ranking on your site, update or write it, run it through SEO checks, shove it into WordPress, then wait to see if anyone reads it. Just six months ago that loop was tedious tab-switching and copy-pasting. … <a title="Best AI PCs for Running Local LLMs" class="read-more" href="https://houtini.com/best-pcs-for-local-ai-tested-specs-for-running-llms-without-the-cloud/" aria-label="Read more about Best AI PCs for Running Local LLMs">Read more</a>
How to Set Up LM Studio: Running AI Models on Your Own Hardware
How does anyone end up running their own AI models locally? For me, it started because of a deep interest in GPUs and powerful computers. I’ve got a machine on my network called “hopper” with six NVIDIA GPUs and 256GB of RAM, and I’d been using it for various tasks already, so the idea of … <a title="Best AI PCs for Running Local LLMs" class="read-more" href="https://houtini.com/best-pcs-for-local-ai-tested-specs-for-running-llms-without-the-cloud/" aria-label="Read more about Best AI PCs for Running Local LLMs">Read more</a>